
Task 1: Dependency Parsing
Task definition
The proposed task consists in creating dependency parsers for Polish. Dependency parsers should be trained on trees from Polish Dependency Bank formatted according to the guidelines of Universal Dependency v2 (http://universaldependencies.org/guidelines.html). The task is open to everyone. Participants can take part in one of two subtasks or in both subtasks. We strongly encourage system developers from Poland and abroad to participate in the task.
Subtask (A): Morphosyntactic prediction of dependency trees
Participating systems will have to predict labelled dependency trees for tokenised sentences and morphosyntactic analyses of the sentences’ tokens. In a dependency tree each node (except for the root node) depends on exactly one governing node (HEAD) and the relation between these nodes is labelled with a universal dependency type possibly with a Polish-specific subtype extension (DEPREL). Morphosyntactic analysis, in turn, consists in predicting universal part-of-speech tags (UPOS), Polish-specific tags (XPOS), morphological features (FEATS), and lemmas (LEMMA) of particular tokens. If participants do not aim at predicting morphosyntactic analysis of Polish tokens, their systems can predict only dependency trees. In the test phase, we will make accessible a file with sentences automatically morphosyntactically analysed with a publically available system, e.g. UDPipe.
Subtask (B): Beyond dependency tree
Participants are encouraged to predict labelled dependency graphs (i.e. dependency trees + possible enhanced edges) and semantic labels which some relations are additionally annotated with. The enhanced edges encode shared dependents of coordinated elements (e.g. Piotr wstał i wyszedł. ‘Piotr stood up and left.’) and shared governors of coordinated elements (e.g. Lubimy babeczki i ciasteczka. `We like cupcakes and cookies.’). The additional semantic labels (e.g. ‘Experiencer’, ‘Place’, ‘Condition’) extend semantic meaning of indirect objects (iobj), oblique nominals (obl), adverbial clause modifiers (advcl), some adverbial modifiers (advmod), some noun modifiers (nmod), etc. Note that the semantic labels are in an additional 11th column of the CoNLL-U format.
Training data
Subtask A
DOWNLOAD: Task 1 (A) - development data
DOWNLOAD: Task 1 (A) - training data
Subtask B
DOWNLOAD: Task 1 (B) - development data
DOWNLOAD: Task 1 (B) - training data
Test data
Test sentences are manually tokenised (gold standard tokens). LEMMA, UPOS, XPOS, and FEATS are automatically predicted with UDPipe 1.2 trained on the training data set.
Subtask A
DOWNLOAD: Task 1 (A) - test data
Subtask B
DOWNLOAD: Task 1 (B) - test data
Evaluation procedure
The participating systems should output trees in CoNLL-U format with the standard 10 columns in the subtask (A) or 11 columns in the subtask (B). Output trees will be evaluated with a slightly modified version of the evaluation script prepared for the purpose of CoNLL 2018 shared task on Multilingual Parsing from Raw Text to Universal Dependencies.
In contrast to CoNLL 2018 shared task, we will evaluate prediction of full dependency labels (universal dependency type + Polish-specific subtype) and all morphological features with LAS, MLAS, and BLEX measures. Additionally, we define two other measures ELAS and SLAS for evaluation of dependency graphs and semantic labels.
ELAS and SLAS are harmonic means (F1) of precision P and recall R:
ELAS = 2PR / (P+R)
ELAS (enhanced labelled attachment score) is designed for the purpose of evaluating dependency graphs with enhanced edges. ELAS is a strict extension of LAS, i.e. a token must be assigned a correct main governor (7th column), main dependency relation (8th column) and a correct set of enhanced governors (9th column). Precision P and recall R are defined as follows.
Precision P is the ratio of the number of the correct words to the total number of the predicted nodes. Recall R is the ratio of the number of the correct words to the total number of the gold standard nodes.
A word is considered to be correct if several conditions are met:
-
a token S is assigned the correct head G and the correct dependency type,
-
a token S is assigned correct enhanced heads EG and the correct enhanced dependency types.
SLAS (semantic-aware labelled attachment score) is defined to evaluate dependency trees with semantic labels. Precision P and recall R are defined as follows.
Precision P is the ratio of the number of correct words to the total number of predicted content words. Recall R is the ratio of the number of the correct words to the total number of the gold standard content words.
A word is considered to be a content word if it fulfils one of the following content functions: nsubj, obj, iobj, csubj, ccomp, xcomp, obl, vocative, expl, dislocated, advcl, advmod, discourse, nmod, appos, nummod, acl, amod, conj, fixed, flat, compound, list, parataxis, orphan, root. A predicted word S is considered to be a correct word, if several conditions are met:
-
S and G fulfil the identical content functions,
-
S and G are correctly labelled with a semantic label or are correctly left unlabelled.
Additional resources
The following additional resources can be used in training dependency parsers of Polish:
- http://universaldependencies.org/conll18/data.html
- http://dsmodels.nlp.ipipan.waw.pl/
- http://mozart.ipipan.waw.pl/~axw/models/
References
Description of CoNLL 2018 shared task on Multilingual Parsing from Raw Text to Universal Dependencies
http://universaldependencies.org/conll18
Task 2: Named Entity Recognition
Task definition
Named entities (NE) are phrases that contain the names of things, such as persons, organizations and locations. Named Entity Recognition (NER) task is to label sequences of words in a text with appropriate named entity markup. Named entity recognition is an important task of information extraction systems.
For example:
[PER Ban Ki-moon] przebywał z wizytą w [LOC Gdańsku].
This sentence contains two named entities: Ban Ki-moon is a person [PER], Gdańsk is a location [LOC].
Entity lemmatization is not a part of this task.
There has been a lot of work on named entity recognition, especially for English. The Message Understanding Conferences (MUC), CoNLL-2002 and CoNLL-2003 [1] have offered the opportunity to evaluate systems for English on the same data in a competition. They have also produced schemes for entity annotation. The PolEval Named Entity Recognition task aims to bridge this gap and provide a reference data set for the Polish language.
Annotating conventions of both training and testing data follow the National Corpus of Polish (NKJP). For a discussion of named entity annotation in NKJP, please refer to chapter 9. by Savary et al. [2]. Please note that NKJP supports nested entity annotation and multiple sub-categories (three sub-types of persons, five sub-types of places, as on figure 9.2 on p. 133 in http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf).
Training data
As the training data set, we encourage to use the manually annotated 1-million word subcorpus of the National Corpus of Polish. It is available from: http://clip.ipipan.waw.pl/NationalCorpusOfPolish
DOWNLOAD: Task 2 - training data
Test data
Test data can be downloaded from the link below. Please make sure to follow the README file to learn about the desired data format as it is different than for the training set (i.e. not TEI). It is a lightweight format with offset information.
Evaluation procedure
We intend to evaluate systems according to two general approaches:
- Exact match of entities: in order to count as a true positive, offsets of detected vs golden entities need to be the same,
- Entity overlap: in order to count as a true positive, offsets of detected vs golden entities need to have a common range, such as a word or more words.
In both cases, in order to count as a true positive, detected category of an entity need to be the same as the golden one.
Final ranking of participating systems will be based on a combined measure of the exact match and entity overlap.
The metrics we are going to use for this task is micro F1.
Other remarks [updated 8.08]
- It is possible and acceptable to use some form of transfer learning, including but not limited to word embeddings trained on different sources than the official training data set.
- We also accept submissions trained on other named-entity data sources. However, systems trained on such extra named entity resources will not be evaluated in the same competition as those trained on official data only.
- We plan not to evaluate "deriv" annotations. This type of annotations was described in chapter 9. of the NKJP book, section "derivative words" ("wyrazy pochodne") and develop into two subtypes (relAdj oraz persDeriv). While present in NKJP, we decided not to take them into account when evaluating submitted systems. Such markings will be ignored by the evaluation script.
- We take into account fragmented entities as such are present in NKJP. However, our data format does not allow to distinguish one fragmented entity from multiple entities, provided they are of the same named entity category. Therefore, we only check categories of all annotated fragments.
References
- Erik F. Tjong Kim Sang and Fien De Meulder. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition.
http://www.aclweb.org/anthology/W03-0419.pdf - Agata Savary, Marta Chojnacka-Kuraś, Anna Wesołek, Danuta Skowrońska, Paweł Śliwiński. Anotacja jednostek nazewniczych. In: Narodowy Korpus Języka Polskiego. Editors: Adam Przepiórkowski and Mirosław Bańko and Rafał L. Górski and Barbara Lewandowska-Tomaszczyk. Wydawnictwo Naukowe PWN, Warsaw. 2012. pp 129-165
http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf
Task 3: Language Models
Task definition
A statistical language model is a probability distribution over sequences of words. Given a set of sentences in Polish in a random order, each with original punctuation, the goal of the task is to create a language model for Polish. Participants are allowed to use any approach to creating the model.
Training data
As the training data set, we have prepared a corpus containing over 20 million sentences in Polish. The corpus consists of a single plain text. The order of the sentences is randomized and their sources will be revealed together with the test data. The punctuation and spelling has been left untouched from the original sources.
DOWNLOAD: Task 3 - training data
UPDATE
We provide the segmented training corpus in the link below. All the tokens (words and punctuation marks) are separated with space.
DOWNLOAD: Task 3 - segmented training data
Data preprocessing should be performed similarly, as in Google One Billion Word Benchmark. Words are assumed to be the basic units of the language model. Punctuation marks are treated as words and they should be a part of language model. A vocabulary should be extracted from the training set. Every word and punctuation mark that occured 3 or more times in the training set should be included in the vocabulary. Additionally, the vocabulary should include sentence boundary markers (<s> - </s>) and the token <UNK> which is used to map Out Of Vocabulary (OOV) words. OOV words are tokens that are present in the training or test set, but not included in the vocabulary.
Test data
DOWNLOAD: Task 3 - segmented test data
Evaluation procedure
The participants are asked to evaluate perplexity of their model on the test set. The model with the lowest perplexity wins the competition. Detailed instructions about perplexity are provided below.
Perplexity is a measure commonly used to estimate the quality of a language model (see e.g. Google One Billion Word Benchmark). Perplexity is the inverse probability of the test set, normalized by the number of words.
The language model should estimate the possibility of occurrence for every word in every sentence. The probability should be calculated for every word and the sentence ending in the test set.
Perplexity can be calculated using below equations:
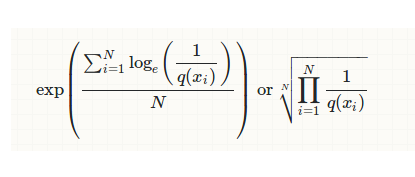
Where
- N - number of samples in the test set,
- X - discrete random variable with possible values {x1, ..., xn},
- q(X) - probability function.
For instance, for the bigram language model perplexity equals:
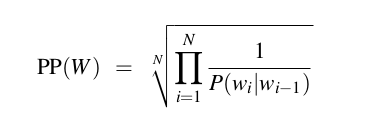
Where
- N - number of words in the testset + number of sentence endings,
- W - the testset {w_1, w_2, ..., w_N},
- P(w_i | w_{i-1}) is the conditional probability of word wi that occurs after word w (i-1).
The participants are asked to map unknown words (OOV words) to and count them as a separate word in the vocabulary. They are also asked to count and provide the OOV (out-of-vocabulary) rate (the number of all words that occur in the test set but don’t occur in the vocabulary divided by all the words in the test set), to ensure that everyone is using the same vocabulary.
For instance, if we calculate the perplexity of the sentence: “I like bananas.” and the word “bananas” would not occur in the vocabulary and the trigam language model is used the perplexity (PPL) is computed as:
PPL = exp {-1/4 [ log P(I | </S> <S>) + log P(like | <S> I) + log P(<UNK> | I like) + log P(</S> | like <UNK>)]}
References
Instructions provided by the authors of the 1-billion-word language modelling benchmark